Why we are building Ravo, an AI research workspace for real papers.
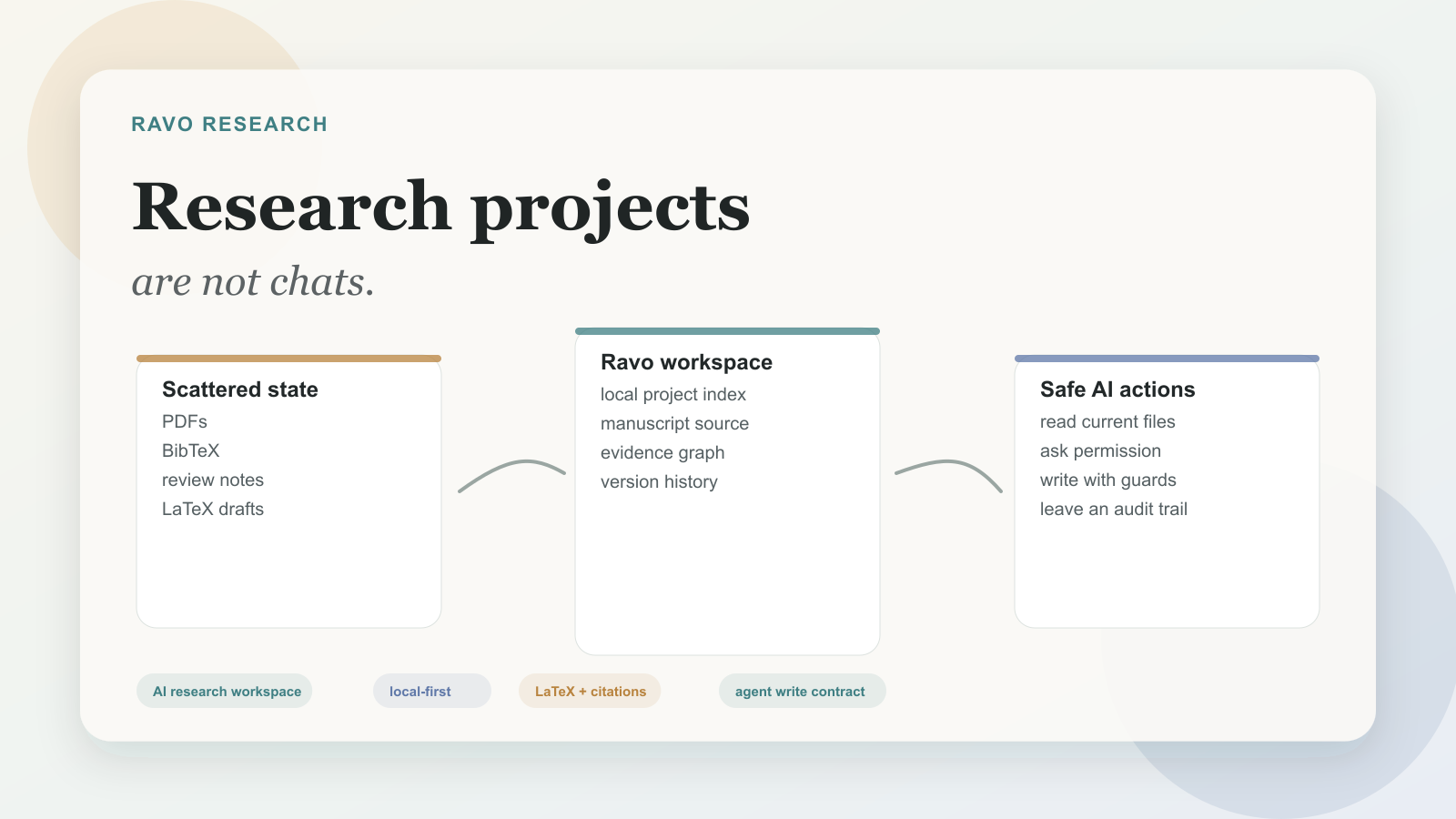
Research projects are not chats. They are long-lived systems of sources, claims, drafts, deadlines, and revisions.
Most products for researchers now start with a chat box. We did not start there.
The first version of Ravo was much smaller. It was a way to track journals, conferences, special issues, and submission deadlines. This looked like a narrow problem. It was not. A deadline is where the whole research workflow becomes visible. To meet one, a researcher has to know the paper, the venue, the coauthors, the references, the formatting rules, the reviewer history, and the state of the draft. If any part is wrong, the date on the calendar is just decoration.
That is why the product kept expanding inward. Deadline tracking led to venue fit. Venue fit led to manuscript readiness. Readiness led to references, PDFs, LaTeX, notes, comments, and version history. Eventually we arrived at the actual object we cared about: not a paper file, but a research project.
A research project is not a document
A document has text. A research project has state.
It has papers you read six months ago and half remember. It has claims that depend on a source. It has a BibTeX file with one broken key. It has a reviewer comment that changed the introduction, a figure that came from an old notebook, and a deadline that moved because a special issue page was updated quietly. It has decisions that are rational at the time, then impossible to reconstruct later.
This is the part a normal chatbot does not see. It can answer a question, but it does not naturally own the surrounding state. It does not know which PDF is the source of truth, whether the LaTeX file changed after it read it, or whether a citation it suggested is actually present in your library. The problem is not only intelligence. The problem is attachment to the project.

Research work is a loop. The hard part is preserving evidence and decisions as the loop repeats.
Why a chatbot feels good and then becomes tiring
The chat interface is powerful because it is unstructured. You can ask anything. This is also its weakness. A research project is full of small contracts. When an assistant summarizes a paper, it should cite the paragraph. When it changes a LaTeX file, it should know which version it read. When it recommends a venue, it should show the scope text and recent examples. When it edits a response letter, it should preserve the reviewer numbering.
Without those contracts, the researcher has to supervise everything manually. The user becomes the integration layer. They copy text from one place, paste it into another, ask the model to revise it, check the file, check the citation, check the deadline, and then do it again tomorrow. That is useful, but it is not a workspace.
We want Ravo to be the workspace. The AI should be able to read the same project the researcher is working in, use the same references, edit the same manuscript, and leave behind a trace of what it did.
The first principle is justified confidence
Researchers do not need more confident software. They need software that earns confidence.
This sounds small, but it changes the design. A recommendation should not be a single number. It should expose the evidence behind the number. A summary should not hide the source. A write operation should not silently overwrite a file that changed. A project assistant should not make the user guess whether it used the current draft or an older one.
The contract we want every AI action to satisfy
- ·What did it read?
- ·What did it change?
- ·Which source supports the claim?
- ·Was the file still the same when it wrote?
- ·What should the researcher review next?
The interface can be simple only if the underlying contract is explicit.
This is why some of the most important work in Ravo is not visible as a large feature. Local project indexing, source-aware retrieval, citation grounding, host file APIs, stale-write guards, permission prompts, and audit events are not glamorous. They are the rails that let an agent operate inside a real project without making the researcher nervous.
Local-first is a product decision, not a slogan
Many researchers will use online AI models. We do too. But the project itself should not become a remote blob owned by a model provider.
Papers, notes, drafts, and review letters often contain unpublished ideas. They also need to remain useful without network access, without a subscription running, and without trusting one vendor forever. So Ravo is built as a desktop workspace first. The project lives on your machine. AI providers are attached to the workspace, not the other way around.
This also gives the system a cleaner shape. The app can manage files directly. It can compile LaTeX. It can keep a version history. It can detect when a file changed since an agent last read it. It can let the researcher choose which model to use for which task. The AI becomes a participant in the workspace, not the database.

For writing agents, safety is mostly bookkeeping. The system has to remember what the model read and refuse stale writes.
What we learned from building the rough version
The rough version taught us that researchers are not asking for magic. They are asking for continuity.
They want the paper they read to be connected to the sentence they are writing. They want the venue they choose to be connected to the deadline and the submission checklist. They want the revision plan to remember reviewer comments. They want the AI to understand the project without being reintroduced to it every session.
This is a more boring product than the demos suggest. It is also a more useful one. The hard thing is not producing a paragraph. The hard thing is making sure the paragraph belongs in the project, cites the right evidence, and does not break the draft.
How we think about agents
An agent in Ravo should not be a personality floating above the work. It should be a set of capabilities grounded in the project.
Sometimes that means a small action: find every citation to a paper, inspect the surrounding claims, and show where the argument is weak. Sometimes it means a longer action: read the current manuscript, compare it to a target venue, produce a readiness checklist, then open the exact files that need changes. In both cases, the agent should move through the project with constraints.
This is also why we care about connecting existing AI agents rather than pretending there will be one permanent provider. Researchers already use different models and tools. Ravo should detect what is available, expose a common event schema, and keep the workspace contract stable underneath. If the provider changes, the project should not.
The product we are trying to make
Ravo is a local-first research workspace for the full path from first search to final submission. It includes references, PDFs, notes, manuscript writing, LaTeX preview, venue discovery, deadline planning, and AI assistance. But the list of features is not the point.
The point is that a research project should have a home. Not a folder full of files, not a chat history, not a reference manager plus a writing app plus a calendar. A home where the state of the project is legible, where AI can help without erasing context, and where the researcher remains the person making the judgment.
We are not trying to replace the researcher. We are trying to make the project easier to think with.
That is the builder story so far. We started with deadlines because they were concrete. We kept building because every deadline pointed back to the same missing object: a workspace that understands the paper as a project.
Ravo is our attempt to build that object.